用户查询优惠券之缓存穿透
业务背景
在上一节中,我们讨论了正常用户在访问优惠券时可能遇到的缓存击穿问题,并介绍了缓存预热、缓存永不过期、分布式锁、双重判定锁、分片分布式锁等技术来应对这些问题。然而,还有一个问题需要解决:如果用户频繁访问数据库中不存在的数据,就无法有效使用缓存,每次都需要访问数据库,这将导致数据库承受较大的压力。这也就是缓存穿透问题。
什么是缓存穿透?
缓存穿透是指由于请求没有办法命中缓存,因此就会直接打到数据库,当请求量较大时,大量的请求就可能会直接把数据库打挂。
通常情况下,缓存是为了提高数据访问速度,避免频繁查询数据库。但如果攻击者故意请求缓存中不存在的数据,就会导致缓存不命中,请求直接访问数据库。
没有经过缓存穿透处理的业务伪代码如下:
public String selectUser(String userId) {
String cacheData = cache.get(userId);
if (StrUtil.isBlank(cacheData)) {
String dbData = userMapper.selectId(userId);
if (StrUtil.isNotBlank(dbData)) {
cahce.set(userId, dbData);
cacheData = dbData;
} else {
throw new RuntimeException();
}
}
return cacheData;
}
缓存穿透常见解决方案
1. 空对象缓存
当查询结果为空时,也将结果进行缓存,但是设置一个较短的过期时间。这样在接下来的一段时间内,如果再次请求相同的数据,就可以直接从缓存中获取,而不是再次访问数据库,可以一定程度上解决缓存穿透问题。
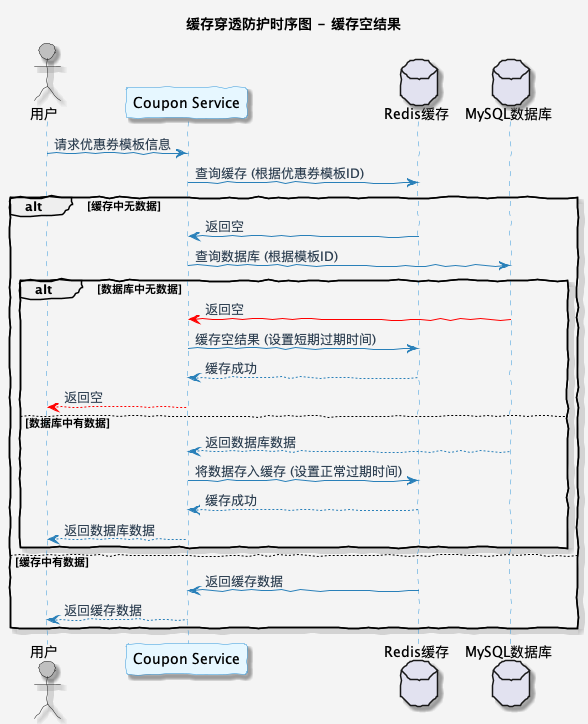 这种方式是比较简单的一种实现方案,会存在一些弊端。那就是当短时间内存在大量恶意请求,缓存系统会存在大量的内存占用。
这种方式是比较简单的一种实现方案,会存在一些弊端。那就是当短时间内存在大量恶意请求,缓存系统会存在大量的内存占用。
2. 布隆过滤器
2.1 什么是布隆过滤器
布隆过滤器是一种数据结构,用于快速判断一个元素是否存在于一个集合中。它以牺牲一定的准确性为代价,换取了存储空间的极大节省和查询速度的显著提升。
具体来说,布隆过滤器包含一个位数组和一组哈希函数。位数组的初始值全部置为 0。在插入一个元素时,将该元素经过多个哈希函数映射到位数组上的多个位置,并将这些位置的值置为 1。
因为每个元素存储都是以位来存储,而不是字节,所以元素的占用空间非常小.
2.2 布隆过滤器优缺点
布隆过滤器的优点在于它可以高效地判断一个元素是否属于一个大规模集合,且具有极低的存储空间要求。如果存储 1亿元素,误判率设置为 0.001 也就是千分之一,仅需要占用 171M 左右的内存。
缺点在于可能会存在一定的误判率。
它在实际应用中常用于缓存场景下缓存穿透问题,对访问请求做一个快速判断机制。
但是布隆过滤器本身也存在一些“弊端”,那就是不支持删除元素。因为它是一种基于哈希的数据结构,删除元素会涉及到多个哈希函数之间的冲突问题,这样会导致删除一个元素可能会影响到其他元素的正确性。
总的来说,布隆过滤器是一种非常高效的数据结构,适用于那些可以容忍一定的误判率的场合。
2.3 布隆过滤器解决缓存穿透
==可以将所有数据库数据全部放入布隆过滤器,然后如果缓存中不存在数据,紧接着判断布隆过滤器是否存在,如果存在访问数据库请求数据,如果不存在直接返回错误响应即可。==
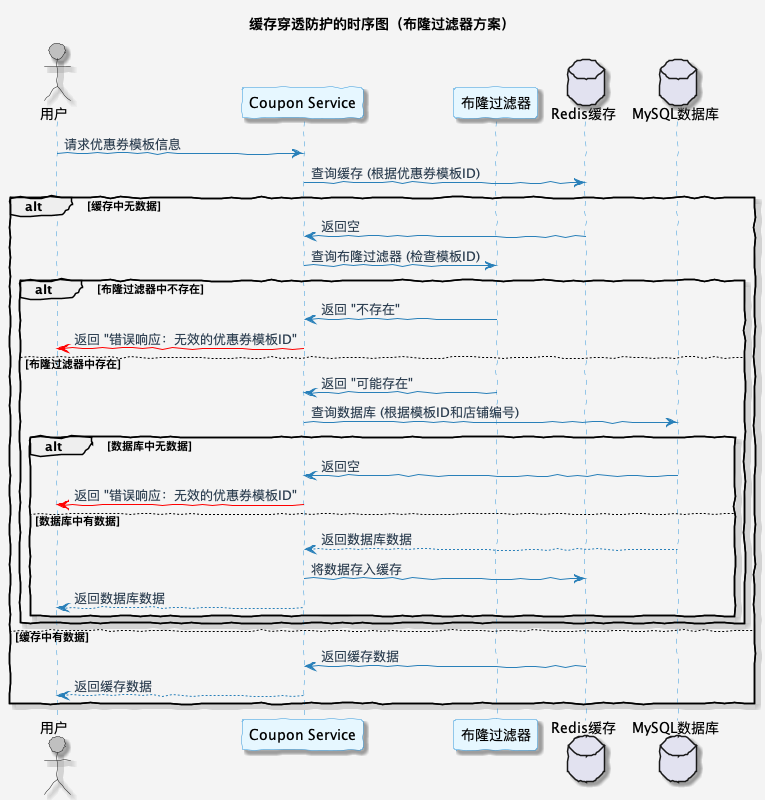 但是这种问题还是会有一些小概率问题,那就是如果使用一种小概率误判的缓存进行攻击,依然会对数据库造成比较大的压力。这个怎么理解呢?
但是这种问题还是会有一些小概率问题,那就是如果使用一种小概率误判的缓存进行攻击,依然会对数据库造成比较大的压力。这个怎么理解呢?
- 比如说一个优惠券 ID 是 1827975299049058306,我通过优惠券 ID 规则,模拟一个不存在的但很相近的,比如 1827975299049058307,去碰撞那个误判的概率;
- 怎么判断这个数据是不是存在?就是看接口的响应时间,布隆过滤器是绝对的毫秒级,比如 5 毫秒,而且性能基本上比较恒定。那我们就可以根据相应时间是否大于 5 毫秒,因为误判了还会查一次数据库;
- 如果查询第一次大于 5 毫秒且数据返回为空,那就证明这是个碰撞漏网之鱼,直接拿高并发访问即可,还是会请求到数据库。
3. 布隆过滤器+空值缓存+分布式锁
如果说缓存不存在,那么就通过布隆过滤器进行初步筛选,然后判断是否存在缓存空值,如果存在直接返回失败。如果不存在缓存空值,使用锁机制避免多个相同请求同时访问数据库。最后,如果请求数据库为空,那么将为空的 Key 进行空对象值缓存。
 多重方案伪代码如下所示:
多重方案伪代码如下所示:
public String selectUser(String userId) {
String cacheData = cache.get(userId);
if (StrUtil.isBlank(cacheData)) {
// 判断 Key 是否存在布隆过滤器,存在则继续流程,否则直接返回
if (!bloomFilter.contains(fullShortUrl)) {
throw new RuntimeException();
}
// 判断 Key 是否包含空值缓存,存在直接返回,不存在继续流程
Boolean cacheIsNull = cache.hasKey("is-null_" + userId);
if (cacheIsNull) {
throw new RuntimeException();
}
// 获取分布式锁
Lock lock = getLock(userId);
lock.lock();
try {
// 拿到锁之后进行双重判定,如果缓存已经存在则直接返回即可
cacheData = cache.get(userId);
if (StrUtil.isBlank(cacheData)) {
String dbData = userMapper.selectId(userId);
if (StrUtil.isNotBlank(dbData)) {
cahce.set(userId, dbData);
cacheData = dbData;
} else {
// 查询数据库中不存在数据,添加空值缓存并返回
cache.set("is-null_" + userId, 较短过期时间);
throw new RuntimeException();
}
}
} finally {
lock.unlock();
}
}
return cacheData;
}
项目实战
1. 创建布隆过滤器
下面这个配置需要在优惠券后管和引擎模块都需要添加,以后管中配置代码举例:
package com.nageoffer.onecoupon.merchant.admin.config;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 布隆过滤器配置类
* <p>
* 作者:马丁
* 加项目群:早加入就是优势!500人内部项目群,分享的知识总有你需要的 <a href="https://t.zsxq.com/cw7b9" />
* 开发时间:2024-08-27
*/
@Configuration
public class RBloomFilterConfiguration {
/**
* 优惠券查询缓存穿透布隆过滤器
*/
@Bean
public RBloomFilter<String> couponTemplateQueryBloomFilter(RedissonClient redissonClient) {
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter("couponTemplateQueryBloomFilter");
bloomFilter.tryInit(640L, 0.001);
return bloomFilter;
}
}
其中 tryInit 有两个参数,代表预估插入量和错误概率,因为会根据这两个参数进行初始化布隆过滤器的位数组,不建议大家设置太大。
1.1 预计插入量
这是一个估计值,表示布隆过滤器预期将会插入的元素总数。
通过知道预期的插入量,布隆过滤器可以根据这个估计值来合理地配置位数组的大小和哈希函数的数量。这样可以在达到指定错误率的情况下,最大限度地节省内存。插入的元素数量如果超出预期,会增加误判的概率。
1.2 误判率
表示布隆过滤器在给定条件下可能返回错误结果的概率。
错误概率用于在布隆过滤器初始化时确定其位数组的大小和哈希函数的数量。较低的误判率意味着需要更大的位数组和更多的哈希函数,从而占用更多的内存和计算时间。反之,较高的误判率则意味着更少的内存占用和计算成本,但错误判定的概率也会增加。
2. 创建优惠券模板添加布隆过滤器
我们创建优惠券模板方法里,需要将优惠券模板 ID 存一份到布隆过滤器中,代码如下:
@Slf4j
@Service
@RequiredArgsConstructor
public class CouponTemplateServiceImpl extends ServiceImpl<CouponTemplateMapper, CouponTemplateDO> implements CouponTemplateService {
// ......
private final RBloomFilter<String> couponTemplateQueryBloomFilter;
@Override
public void createCouponTemplate(CouponTemplateSaveReqDTO requestParam) {
// ......
// 添加优惠券模板 ID 到布隆过滤器
couponTemplateQueryBloomFilter.add(String.valueOf(couponTemplateDO.getId()));
}
}
3. 改造优惠券模板查询缓存穿透
我们先写一个单独的缓存穿透解决方案,后面再和击穿逻辑结合一起。
查询优惠券模板请求第一步,判断布隆过滤器是否存在指定模板 ID,不存在直接返回错误。
@Slf4j
@Service
@RequiredArgsConstructor
public class CouponTemplateServiceImpl extends ServiceImpl<CouponTemplateMapper, CouponTemplateDO> implements CouponTemplateService {
private final RBloomFilter<String> couponTemplateQueryBloomFilter;
@Override
public CouponTemplateQueryRespDTO findCouponTemplate(CouponTemplateQueryReqDTO requestParam) {
if (!couponTemplateQueryBloomFilter.contains(requestParam.getCouponTemplateId())) {
throw new ClientException("优惠券模板不存在");
}
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, Long.parseLong(requestParam.getShopNumber()))
.eq(CouponTemplateDO::getId, Long.parseLong(requestParam.getCouponTemplateId()))
.eq(CouponTemplateDO::getStatus, CouponTemplateStatusEnum.ACTIVE.getStatus());
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
return BeanUtil.toBean(couponTemplateDO, CouponTemplateQueryRespDTO.class);
}
}
4. 改造组合方案
我们在这个方法里,引入缓存布隆过滤器、空值以及分布式锁逻辑,应用到我们的优惠券模板查询解决方案中。
代码看着挺多,但是都是按照我们上面讲的布隆过滤器、控制缓存、分布式锁逻辑一步步来的。
@Slf4j
@Service
@RequiredArgsConstructor
public class CouponTemplateServiceImpl extends ServiceImpl<CouponTemplateMapper, CouponTemplateDO> implements CouponTemplateService {
private final CouponTemplateMapper couponTemplateMapper;
private final StringRedisTemplate stringRedisTemplate;
private final RedissonClient redissonClient;
private final RBloomFilter<String> couponTemplateQueryBloomFilter;
@Override
public CouponTemplateQueryRespDTO findCouponTemplate(CouponTemplateQueryReqDTO requestParam) {
// 查询 Redis 缓存中是否存在优惠券模板信息
String couponTemplateCacheKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId());
Map<Object, Object> couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
// 如果存在直接返回,不存在需要通过布隆过滤器、缓存空值以及双重判定锁的形式读取数据库中的记录
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
// 判断布隆过滤器是否存在指定模板 ID,不存在直接返回错误
if (!couponTemplateQueryBloomFilter.contains(requestParam.getCouponTemplateId())) {
throw new ClientException("优惠券模板不存在");
}
// 查询 Redis 缓存中是否存在优惠券模板空值信息,如果有代表模板不存在,直接返回
String couponTemplateIsNullCacheKey = String.format(EngineRedisConstant.COUPON_TEMPLATE_IS_NULL_KEY, requestParam.getCouponTemplateId());
Boolean hasKeyFlag = stringRedisTemplate.hasKey(couponTemplateIsNullCacheKey);
if (hasKeyFlag) {
throw new ClientException("优惠券模板不存在");
}
// 获取优惠券模板分布式锁
RLock lock = redissonClient.getLock(String.format(EngineRedisConstant.LOCK_COUPON_TEMPLATE_KEY, requestParam.getCouponTemplateId()));
lock.lock();
try {
// 双重判定空值缓存是否存在,存在则继续抛异常
hasKeyFlag = stringRedisTemplate.hasKey(couponTemplateIsNullCacheKey);
if (hasKeyFlag) {
throw new ClientException("优惠券模板不存在");
}
// 通过双重判定锁优化大量请求无意义查询数据库
couponTemplateCacheMap = stringRedisTemplate.opsForHash().entries(couponTemplateCacheKey);
if (MapUtil.isEmpty(couponTemplateCacheMap)) {
LambdaQueryWrapper<CouponTemplateDO> queryWrapper = Wrappers.lambdaQuery(CouponTemplateDO.class)
.eq(CouponTemplateDO::getShopNumber, Long.parseLong(requestParam.getShopNumber()))
.eq(CouponTemplateDO::getId, Long.parseLong(requestParam.getCouponTemplateId()))
.eq(CouponTemplateDO::getStatus, CouponTemplateStatusEnum.ACTIVE.getStatus());
CouponTemplateDO couponTemplateDO = couponTemplateMapper.selectOne(queryWrapper);
// 优惠券模板不存在或者已过期加入空值缓存,并且抛出异常
if (couponTemplateDO == null) {
stringRedisTemplate.opsForValue().set(couponTemplateIsNullCacheKey, "", 30, TimeUnit.MINUTES);
throw new ClientException("优惠券模板不存在或已过期");
}
// 通过将数据库的记录序列化成 JSON 字符串放入 Redis 缓存
CouponTemplateQueryRespDTO actualRespDTO = BeanUtil.toBean(couponTemplateDO, CouponTemplateQueryRespDTO.class);
Map<String, Object> cacheTargetMap = BeanUtil.beanToMap(actualRespDTO, false, true);
Map<String, String> actualCacheTargetMap = cacheTargetMap.entrySet().stream()
.collect(Collectors.toMap(
Map.Entry::getKey,
entry -> entry.getValue() != null ? entry.getValue().toString() : ""
));
// 通过 LUA 脚本执行设置 Hash 数据以及设置过期时间
String luaScript = "redis.call('HMSET', KEYS[1], unpack(ARGV, 1, #ARGV - 1)) " +
"redis.call('EXPIREAT', KEYS[1], ARGV[#ARGV])";
List<String> keys = Collections.singletonList(couponTemplateCacheKey);
List<String> args = new ArrayList<>(actualCacheTargetMap.size() * 2 + 1);
actualCacheTargetMap.forEach((key, value) -> {
args.add(key);
args.add(value);
});
// 优惠券活动过期时间转换为秒级别的 Unix 时间戳
args.add(String.valueOf(couponTemplateDO.getValidEndTime().getTime() / 1000));
// 执行 LUA 脚本
stringRedisTemplate.execute(
new DefaultRedisScript<>(luaScript, Long.class),
keys,
args.toArray()
);
couponTemplateCacheMap = cacheTargetMap.entrySet()
.stream()
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
}
} finally {
lock.unlock();
}
}
return BeanUtil.mapToBean(couponTemplateCacheMap, CouponTemplateQueryRespDTO.class, false, CopyOptions.create());
}
}
常见问题
1. 布隆过滤器设置多大容量?
布隆过滤器的容量就取决于业务的数量,我们之前在分库分表的章节上说,可能有 300 亿的优惠券模板数量,是不是直接设置为布隆过滤器的容量就好了?
不行的,你可以尝试下设置 300 亿预估元素以及千分之一的误判率,绝对会报错。因为
Bloom filter size can't be greater than 4294967294. But calculated size is 431327626981
简单梳理了下,意思是:布隆过滤器大小不能超过 4294967294,但是咱们的参数 300 亿预估值和 千分之一的误判率,已经超过了这个数据。
如果设置 300 亿数据预估值但是设置百分之一的误判率,那么报错就换了一个。可以看到布隆过滤器给我们设置了上限,不能超过。
Bloom filter size can't be greater than 4294967294. But calculated size is 287551751321
小知识点,一个亿的元素,如果千分之一的误判率,那么实际容量大概在 170M 左右。另外在对布隆过滤器进行初始化的时候,会一次性申请对应的内存,这个需要额外注意下,避免初始化超大容量布隆过滤器时内存不足问题。
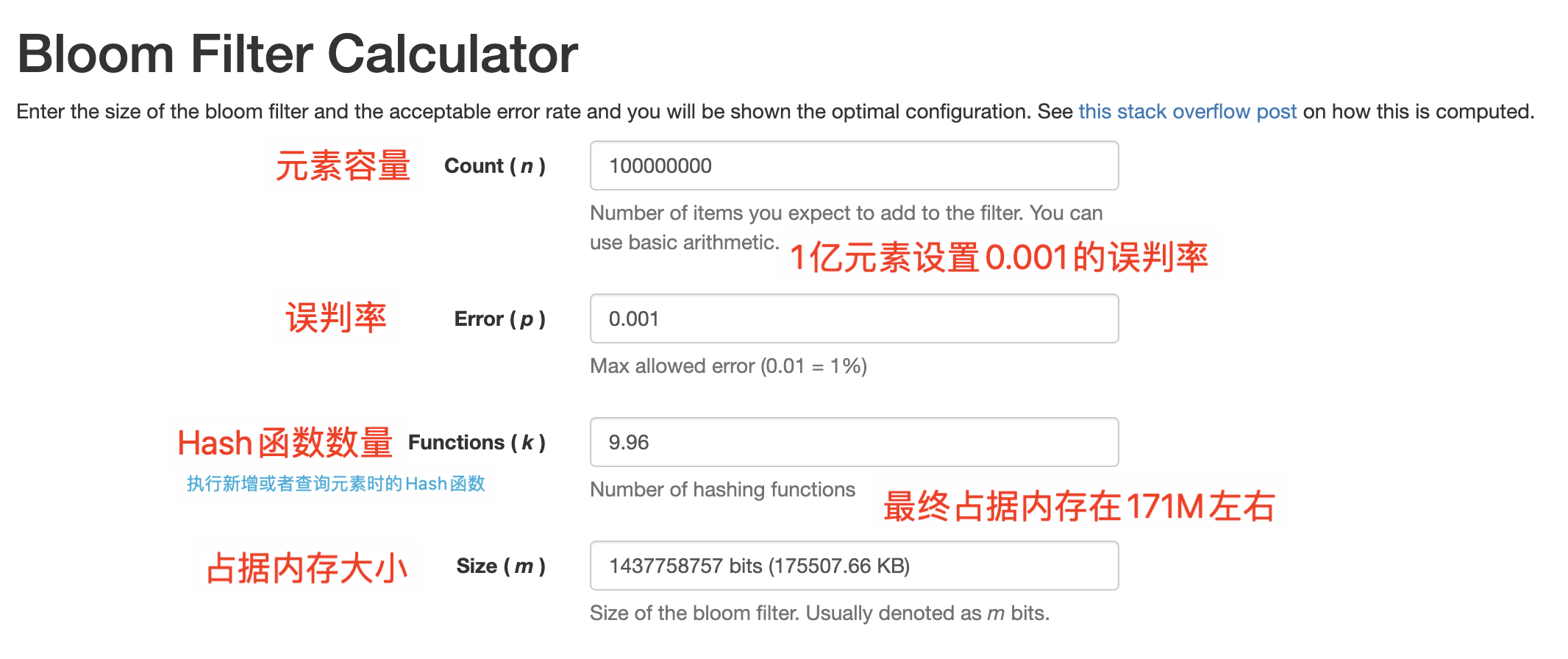
那这种情况下如何解决布隆过滤器不能设置 300 亿数据问题?
可以像之前在处理缓存击穿时所用的分片逻辑一样,设置多个布隆过滤器,使得这些分片的布隆过滤器总容量能达到 300 亿。然后根据模板 ID 进行分片,确定要操作的布隆过滤器,从而在该分片上进行操作。
2. 分布式锁 lock 会触发长时间阻塞么?
这个逻辑和缓存击穿里的逻辑是一样的,大家可以参考缓存击穿章节中的 tryLock 和分布式锁分片处理方案。