分库分表
业务说明
创建优惠券的主力是商家用户,按照淘宝、天猫非官方数据统计,商家数量已有近 3000万。我们假设每个商家会创建 100 张优惠券,那优惠券模板表就会接近 300 亿数据量。
为什么是假设?因为优惠券创建行为隶属于每一个商家,不管是平台还是任何人,都只能以常规数据进行推测。
这个推测也是具备时效性的,随着时间的推迟,商家会更多,同时创建的优惠券也可能会更多,预估数据也会随之增加。
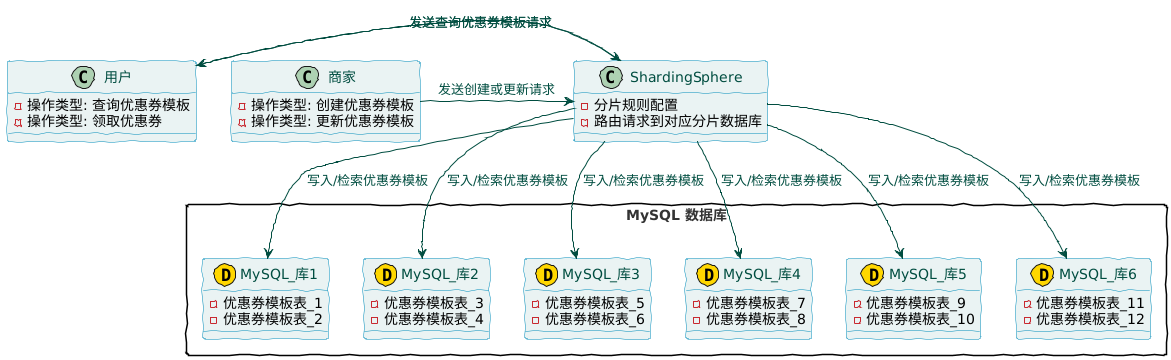
分库分表概述
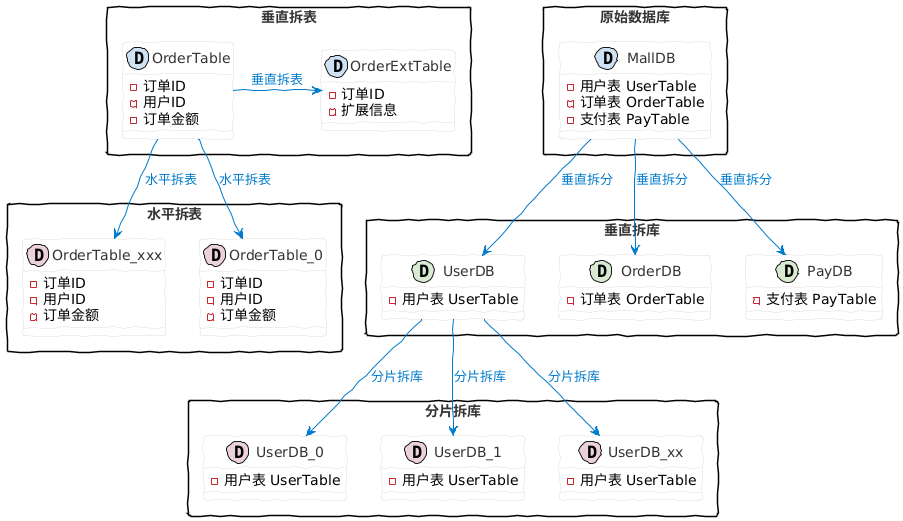
分库有两种模式:
- 垂直拆库:电商库 MallDB,业务拆分后就是 UserDB、OrderDB、PayDB 等。
- 分片拆库:用户库 UserDB,分片库后就是 UserDB_0、UserDB_1、UserDB_xx。
分表也有两种模式:
- 垂直拆分:订单表 OrderTable,拆分后就是 OrderTable 以及 OrderExtTable。
- 水平拆分:订单表 OrderTable,拆分后就是 OrderTable_0、 OrderTable_xxx。
1. 什么场景分表?
当出现以下三种情况的时候,我们需要考虑分表:
- 单表的数据量过大。
- 单表存在较高的写入场景,可能引发行锁竞争。
- 当表中包含大量的 TEXT、LONGTEXT 或 BLOB 等大字段。
2. 什么场景分库?
当出现以下两种情况时,我们需要考虑通过分库来将数据分散到多个数据库实例上,以提升整体系统的性能:
- 当单个数据库支持的连接数已经不足以满足客户端需求。
- 数据量已经超过单个数据库实例的处理能力。
3. 什么场景分库分表?
当出现以下两种场景下,需要进行分库又分表:高并发写入和海量数据:
- 高并发写入场景:当应用面临高并发的写入请求时,单一数据库可能无法满足写入压力,此时可以将数据按照一定规则拆分到多个数据库中,每个数据库处理部分数据的写入请求,从而提高写入性能。
- 海量数据场景:随着数据量的不断增加,单一数据库的存储和查询性能可能逐渐下降。此时,可以将数据按照一定的规则拆分到多个表中,每个表存储部分数据,从而分散数据的存储压力,提高查询性能。
分库分表设计
1. 如何选择分片键?
- 数据均匀性:分片键应该保证数据的均匀分布在各个分片上,避免出现热点数据集中在某个分片上的情况。
- 业务关联性:分片键应该与业务关联紧密,这样可以避免跨分片查询和跨库事务的复杂性。
- 数据不可变:一旦选择了分片键,它应该是不可变的,不能随着业务的变化而频繁修改。
2. 分库分表算法?
分库分表的算法会根据业务的不同而变化,所以并没有固定算法。在业界里用的比较多的有两种:
- HashMod:通过对分片键进行哈希取模的分片算法。
- 时间范围: 基于时间范围分片算法。
分片算法讲解一个数据均匀,时间范围并不适合优惠券模板业务,因为商家用户前期比较少,后面会越来越多,所以有比较明显的不均匀问题。
优惠券模板如何分库分表?
1. 优惠券模板分多少表?
根据上面数据估算,300 亿数据量需要分多少个表?这其实又会涉及到一个知识点,那就是 SQL 复杂么?
- SQL 复杂,拆分百万级别。
- SQL 不复杂,全部走索引,千万甚至亿级别。
我们以优惠券模板举例,不涉及复杂 SQL,但是依然不建议大家数据量到达亿级别,总归要留有余量。在这里我们取经验值 2000 万,300 亿数据就是拆分 150 张表即可。
为什么取 2000 万?其实数据量不是特别多的情况下,基本上 3 次磁盘 IO 就能获取到数据。再多的话可能磁盘 IO 会增加,但是还好。考虑到数据库表备份等其他操作,不建议单表太多数据。
2. 优惠券模板是否需要分库?
不需要,因为并发不高。
如果需要分析一个业务场景如何分库,那就需要知道单个 MySQL Server 的瓶颈是多少?通过之前压测得知,单台 MySQL Server 的写瓶颈大概在 4000-5000/TPS,查询可能更高一些。
如果我们的场景业务每秒 TPS 在 1 万,那么就需要至少分两个库,然后将上面的 150 张表分别放入即可。
3. 优惠券模板表分片键如何选择?
答案呼之欲出,那就是店铺编号字段。
ShardingSphere 项目实战
1. 初始化数据库&表
2. 引入 ShardingSphere Maven Jar 依赖
3. 变更 Application.yaml 和创建 ShardingSphere 配置文件
==shardingsphere-config.yaml 数据库分片配置文件详解。==
# 数据源集合
dataSources:
# 自定义数据源名称,可以是 ds_0 也可以叫 datasource_0 都可以
ds_0:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/one_coupon_rebuild_0?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
ds_1:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/one_coupon_rebuild_1?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
rules:
- !SHARDING
tables: # 需要分片的数据库表集合
t_coupon_template: # 优惠券模板表
# 真实存在数据库中的物理表
actualDataNodes: ds_${0..1}.t_coupon_template_${0..8}
databaseStrategy: # 分库策略
standard: # 单分片键分库
shardingColumn: shop_number # 分片键
shardingAlgorithmName: coupon_template_database_mod # 库分片算法名称,对应 rules[0].shardingAlgorithms
tableStrategy: # 分表策略
standard: # 单分片键分表
shardingColumn: shop_number # 分片键
shardingAlgorithmName: coupon_template_table_mod # 表分片算法名称,对应 rules[0].shardingAlgorithms
shardingAlgorithms: # 分片算法定义集合
coupon_template_database_mod: # 优惠券分库算法定义
== type: HASH_MOD # 基于 Hash 方式分片==
props:
sharding-count: 2 # 一共有 2 个库
coupon_template_table_mod: # 优惠券分表算法定义
== type: HASH_MOD # 基于 Hash 方式分片==
props:
sharding-count: 8 # 单库 8 张表
props:
# 配置 ShardingSphere 默认打印 SQL 执行语句
sql-show: true
==上文的分片算法:HASH_MOD==
解释下其中涉及到的行表达式:
-
ds_${0..1} 意味着 ds_0、ds_1。
-
t_coupon_template_${0..8} 同上。
-
上面数据库分片数据源配置填的
ds_0、ds_1就是逻辑库,one_coupon_rebuild_0、one_coupon_rebuild_1对应物理库。我们是没有变更任何业务代码的,所以逻辑 SQL 里的表名依然是
t_coupon_template,也就是逻辑表。真实 SQL 里的t_coupon_template_6是物理表。物理表也叫做真实表,指的是数据库中真实存在的表。
4. 数据分片不均匀问题
如果用默认的分片算法会存在数据不均匀问题。
表象就是 0 库的奇数表没有数据,1 库的偶数表没有值。
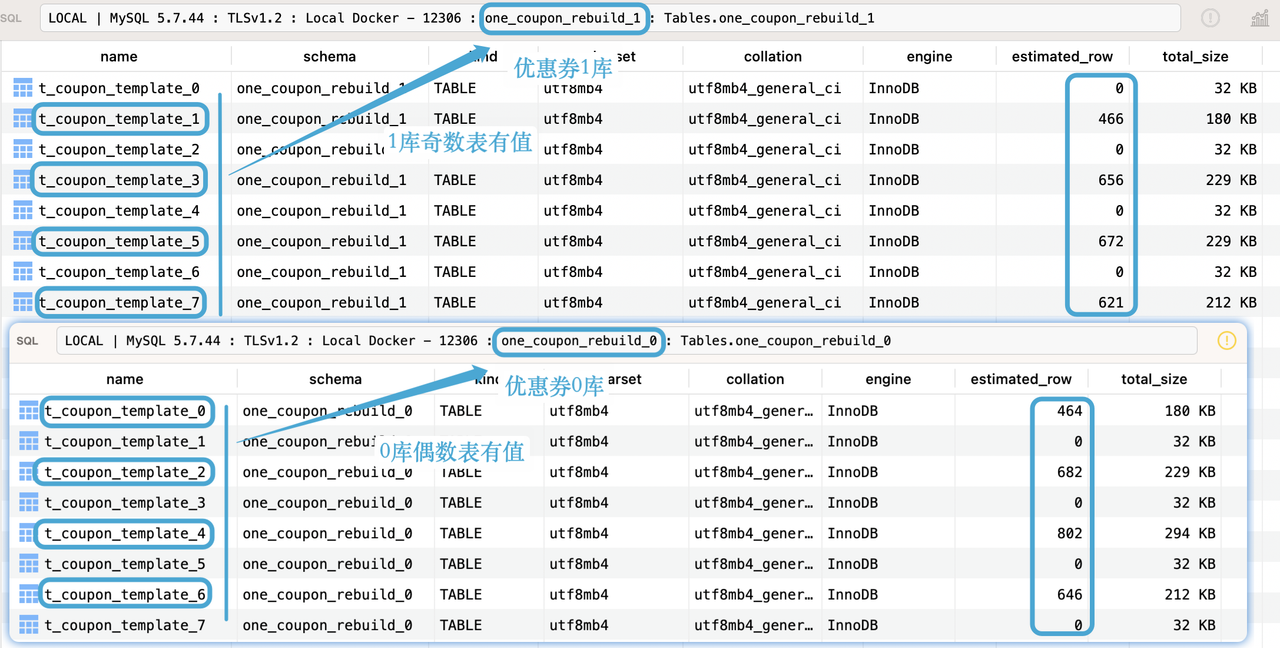
因为我们的分片键店铺编号经过数据库 Hash 后已经确定是奇数还是偶数了,所以哪怕 Hash 的数值(库和表数量)变了,但是依然只能是奇数和偶数。
所以这里我们需要变更 Hash 算法,通过自定义的 Hash 算法扰动分片结果。
有两个变更点,那就是数据库表的分片从每个数据库的 0..8 变更为所有数据库里的表 0..16,以及从框架自带的 HashMod 分片算法修改为自定义分片算法。分片规则见下文所示。
rules:
- !SHARDING
tables: # 需要分片的数据库表集合
t_coupon_template: # 优惠券模板表
# 真实存在数据库中的物理表
actualDataNodes: ds_${0..1}.t_coupon_template_${0..15}
databaseStrategy: # 分库策略
standard: # 单分片键分库
shardingColumn: shop_number # 分片键
shardingAlgorithmName: coupon_template_database_mod # 库分片算法名称,对应 rules[0].shardingAlgorithms
tableStrategy: # 分表策略
standard: # 单分片键分表
shardingColumn: shop_number # 分片键
shardingAlgorithmName: coupon_template_table_mod # 表分片算法名称,对应 rules[0].shardingAlgorithms
shardingAlgorithms: # 分片算法定义集合
coupon_template_database_mod: # 优惠券分库算法定义
type: CLASS_BASED # 根据自定义库分片算法类进行分片
props: # 分片相关属性
# 自定义库分片算法Class
algorithmClassName: com.nageoffer.onecoupon.merchant.admin.dao.sharding.DBHashModShardingAlgorithm
sharding-count: 16 # 分片总数量
strategy: standard # 分片类型,单字段分片
coupon_template_table_mod: # 优惠券分表算法定义
type: CLASS_BASED # 根据自定义库分片算法类进行分片
props: # 分片相关属性
# 自定义表分片算法Class
algorithmClassName: com.nageoffer.onecoupon.merchant.admin.dao.sharding.TableHashModShardingAlgorithm
strategy: standard # 分片类型,单字段分片
自定义算法
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
long id = shardingValue.getValue(); // 分片键值,也就是商家店铺编号
int dbSize = availableTargetNames.size(); // 一共有多少个真实的数据库,咱们就两个 ds_0、ds_1
int mod = (int) hashShardingValue(id) % shardingCount / (shardingCount / dbSize); // 取模
int index = 0;
// 通过刚才的数据库下标,获取到数据库逻辑名称 ds_0 或者 ds_1
for (String targetName : availableTargetNames) {
if (index == mod) {
return targetName;
}
index++;
}
throw new IllegalArgumentException("No target found for value: " + id);
}
在 doSharding 方法中:
首先,我们从 PreciseShardingValue 对象中提取出分片键值(id),也就是商家的店铺编号。
接着,我们获取了 availableTargetNames 集合的大小,也就是数据库的数量。在本例中,有两个数据库:ds_0 和 ds_1。
然后,我们使用 hashShardingValue 方法对 id 进行哈希操作,并将结果取模。
接着,我们将取模的结果除以 (shardingCount / dbSize),以得到一个介于 0 到 dbSize - 1 之间的数值。
最后,我们通过 index 值来找到并返回与 mod 值相对应的数据库的逻辑名称。如果找不到匹配的数据库,则抛出 IllegalArgumentException 异常。
==至此,解决数据不均匀问题。==
5. 如果查询不走分片键会有什么问题?
会出现查询所有分片库的所有分片表,通过 UNION ALL 的形式关联,该举动存在读扩散问题,所以我们的查询一定要带上分片键。
读扩散 SQL 示例如下:
SELECT
*
FROM
`t_coupon_template_0`
WHERE
name = '测试'
UNION ALL
SELECT
*
FROM
`t_coupon_template_1`
WHERE
name = '测试'
UNION ALL
SELECT
*
FROM
`t_coupon_template_2`
WHERE
name = '测试'
UNION ALL
SELECT
*
FROM
`t_coupon_template_x`
WHERE
name = '测试'